cross validation drop in accuracy on test set|cross validation vs testing accuracy : member club For some reason, I cannot reliably use 5-fold cv accuracy as a representor of the test set accuracy. What I mean is, as an example, when I drop a particular feature from the dataset, my cv accuracy increases from 0.7923 to 0.8048. However, my test set accuracy . WEBPayback (2023) será o sétimo evento pay-per-view (PPV) de luta profissional Payback e evento de transmissão ao vivo produzido pela WWE.Será realizado para lutadores das divisões de marca Raw e SmackDown da promoção. O evento acontecerá durante o fim de semana do Dia do Trabalho no sábado, 2 de setembro de 2023, na PPG Paints Arena .
{plog:ftitle_list}
WEBWeight. 102 kg. Nationality. American. Hair Color. Dark Brown. Eye Color. Dark Brown. Gracie Bon is a Panamanian plus-size model who is widely recognized for the bikini and fashion modeling pictures that she uploads to her Instagram account titled graciebon on which she had amassed close to 1.5 million followers by April 2021.
For some reason, I cannot reliably use 5-fold cv accuracy as a representor of the test set accuracy. What I mean is, as an example, when I drop a particular feature from the dataset, my cv accuracy increases from 0.7923 to 0.8048. However, my test set accuracy .The test accuracy must measure performance on unseen data. If any part .I consistently achieve decent validation accuracy but significantly lower .Another possibility is that you did both the cross validation and the evaluation on .
You CAN keep a test set separate for final evaluation and use cross-validation on only training data as suggested here. A test set should still be held out for final evaluation, . The test accuracy must measure performance on unseen data. If any part of training saw the data, then it isn't test data, and representing it as such is dishonest. Allowing the validation set to overlap with the training set .
I consistently achieve decent validation accuracy but significantly lower accuracy on the test set. I've been performing validation like this: 1) Standardize the training data; store the mean and variance (in an sklearn . Another possibility is that you did both the cross validation and the evaluation on the test set incorrectly. I am slighty alarmed by I have 1110 examples of matches from the . Cross-validation (CV) is a technique to assess the generalizability of a model to unseen data. This technique relies on assumptions that may not be satisfied when studying genomics.
Note that Cross Validation especially applies mostly to three cases: • When there is little (test) data. • When you want uncertainty on performance. • When accurate performance measure is . Typically, the use of cross-validation would happen in the following situation: consider a large dataset; split it into train and test, and perform k-fold cross-validation on the .
To get accuracy: Photo by Niklas Tidbury on Unsplash. accuracy = correct_predictions / total_predictions. Accuracy is the proportion of correct predictions over total predictions. This is how we.How to interpret a test accuracy higher than training set accuracy. Most likely culprit is your train/test split percentage. Imagine if you're using 99% of the data to train, and 1% for test, . Cross-validation and hyperparameter tuning are essential techniques for selecting the best model and avoiding overfitting. They help ensure that your model performs well on unseen data without drop in performance. Cross Validation. Using a single train-test split results in a high variance model that’s influenced (more than desired) by the .
The accuracy and Cross-Validation dropped by approximately 5%. I had 80% accuracy and an Cross-Val-Score of 0.8. After removing the outliers from the 3 most important_features (RF's feature_importance) the . Suppose that I have splitted my dataset into training, validation and test set. Now I have trained a network, and then performed a set of hyperparameter tuning on the validation set. I have reached a pretty good performance on the validation set. Then finally you run it on the test set and it gave you a pretty large drop in accuracy. In reality you need a whole hierarchy of test sets. 1: Validation set - used for tuning a model, 2: Test set, used to evaluate a model and see if you should go back to the drawing board, 3: Super-test set, used on the final-final algorithm to see how good it is, 4: hyper-test set, used after researchers have been developing MNIST algorithms for .
If the training set, validation set and the unseen test set (as you put it) have the same score, but lower than you expected then the model has not overfitted.. An overfitted model would have higher scores for the training data at least, and depending on how you optimised the hyper parameters on the validation data but lower for the unseen test set. I am training a model to solve binary classification problem usign scikitlearn, and i wish to perform cross validation with 5 folds. As metrics, i would like to get both the average accuracy and a confusion matrix over the 5 folds.However, depending on the training/validation methodology you employ, the ratio may change. For example: if you use 10-fold cross validation, then you would end up with a validation set of 10% at each fold. There has been some research into what is the proper ratio between the training set and the validation set: However the cross-validation result is more representative because it represents the performance of the system on the 80% of the data instead of just the 20% of the training set. Moreover, if I change the split of my sets, the different test accuracies I get have a high variance but the average cross validation accuracy is more stable.
Training, Validation, and Test data set Cross validation . a more accurate evaluation with smaller uncertainties (by factor 1/sqrt(5)). Now you conclude, that model #1 is the best. and that model #2 is worst! Model # 1 2 3 N Loss Note that Cross Validation especially applies mostly to
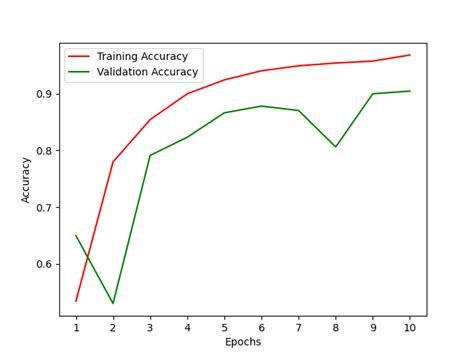
For some reason, I cannot reliably use 5-fold cv accuracy as a representor of the test set accuracy. What I mean is, as an example, when I drop a particular feature from the dataset, my cv accuracy increases from 0.7923 to 0.8048. However, my test set accuracy decreases from 0.8026 to 0.7961. Red is for the training set and blue is for the test set. By showing the accuracy, I had the surprise to get a better accuracy for epoch 1000 compared to epoch 50, even for the test set! To understand relationships between cross entropy and accuracy, I have dug into a simpler model, the logistic regression (with one input and one output).
Finally, the test data set is a data set used to provide an unbiased evaluation of a final model fit on the training data set. If the data in the test data set has never been used in training (for example in cross-validation), the test data set is also called a holdout data set. — “Training, validation, and test sets”, Wikipedia For example, Model A has a 56% accuracy on validation sets, and 57% accuracy on test sets. That's good. I wanted to improve the model, so I made Model B. I added some variables, re-tuned the hyperparameters and achieved an accuracy of 58.5% with Model B on the validation set. Then, I see that Model B has an abysmal 46% accuracy on the test set.Here is a visualization of the cross-validation behavior. Note that ShuffleSplit is not affected by classes or groups. ShuffleSplit is thus a good alternative to KFold cross validation that allows a finer control on the number of iterations and the proportion of samples on each side of the train / test split.. 3.1.2.2. Cross-validation iterators with stratification based on class labels#
validation accuracy test results
Cross validation solves this, you have your train data to learn parameters, and test data to evaluate how it does on unseen data, but still need a way to experiment the best hyper parameters and architectures: you take a sample of your training data and call it cross validation set, and hide your test data , you will NEVER use it until the end. But it is not clear how the test dataset should be used, nor how this approach is better than cross-validation over the whole data set. Let's say we have saved 20% of our data as a test set. Then we take the rest, split it into k folds and, using cross-validation, we find the model that makes the best prediction on unknown data from this dataset. Cross Validation is Superior To Train Test Split. Cross-validation is a method that solves this problem by giving all of your data a chance to be both the training set and the test set. In cross-validation, you .
Output. K-Fold. in the above code, we used matplotlib to visualize the sample plot for indices of a k-fold cross-validation object. We generated training or test visualizations for each CV split. Here, we filled the indices with training or test groups using Numpy and plotted the indices using the scatter() method. The cmap parameter specifies the color of the training and .
Likely you will not only need to split into train and test, but also cross validation to make sure your model generalizes. Here I am assuming 70% training data, 20% validation and 10% holdout/test data. Check out the np.split: If indices_or_sections is a 1-D array of sorted integers, the entries indicate where along axis the array is split.Thanks @MaxU. I'd like to mention 2 things to keep things simplified. First, use np.random.seed(any_number) before the split line to obtain same result with every run. Second, to make unequal ratio like train:test:val::50:40:10 use [int(.5*len(dfn)), int(.9*len(dfn))].Here first element denotes size for train (0.5%), second element denotes size for val (1-0.9 = 0.1%) and . Generally speaking, cross-validation (CV) is used for one of the following two reasons: Model tuning (i.e. hyperparameter search), in order to search for the hyperparameters that maximize the model performance; in scikit-learn, this is usually accomplished using the GridSearchCV module; Performance assessment of a single model, where you are not . Typically, the use of cross-validation would happen in the following situation: consider a large dataset; split it into train and test, and perform k-fold cross-validation on the train set only. The optimization of your model's hyperparameters is guided by the cross-validation score. Once you get the optimal hyperparameters setting, train your .
A better approach is to use nested cross-validation, so that the outer cross-validation provides an estimate of the performance obtainable using a method of constructing the model (including feature selection) and the inner cross-validation is used to select the features independently in each fold of the outer cross-validation. Validation sets are a common sight in professional and academic models. Validation sets are taken out of the training set, and used during training to validate the model's accuracy approximately. The testing set is fully disconnected until the model is finished training - but the validation set is used to validate it during training. Let us now perform the three fold cross-validation by splitting the data using TimeSeriesSplit. Then find out how many values are there in each fold. The number of observations in test set will be generally the same (36 in this case as shown in the below results), while the number of observations in training sets will differ (36, 72 and 108). $\begingroup$ You can also do cross-validation to select the hyper-parameters of your model, then you validate the final model on an independent data set. The recommendation is usually to split the data in three parts, training, test and validation test sets. Use one for training the parameters of the model, one for model selection and finally one for validation of the final .
e) Use K-fold for cross-validation. I divided the data: as follows: Suppose I have 100 data: 10 for testing, 18 for validation, 72 for training. Problem is: Baseline MSE= 14.0 Accuracy on Training set = 0.0012 Accuracy on validation set = 6.45 Accuracy on testing set = 17.12
Box Compression Tester vendor
Box Compression Tester wholesaler
WEB22 de out. de 2023 · Damn I've seen other derpixon shit and he makes some good stuff I font even watch it for porn I watch it because it's like a cool hanime. Derpixion is just the .
cross validation drop in accuracy on test set|cross validation vs testing accuracy